机器学习:决策树_信息熵
机器学习,决策树,信息熵。
熵,形容混乱的程度。越混乱,熵值越高。例子:烧开水,有刚开始加热前水分子结构是稳定的,温度上升则呈现水分子则越来越活跃。
信息熵,熵值越大,数据不确定性越高,信息量越大,反之亦然。这里的数据是指数据集中的目标值,因此对于数据集来说(基于ID3树),数据不确定性越高,信息量越大,熵值越大。(比如:猫狗分类,数据集10个样本,8个是猫,1个狗,数据确定性过高,不符合训练集要求,模型训练出来大概率预测猫)
信息熵,计算公式:
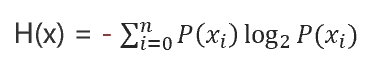
P(x) 数据类别出现的概率(在数据集中就是目标值)。
H(x) 计算后得到的熵值。
公式的意义是,单个目标值出现的概率乘以概率的对数,再加总所有的积,最后加上负号。